
A word boundary \b is a test, just like ^ and $.
When the regexp engine (program module that implements searching for regexps) comes across \b, it checks that the position in the string is a word boundary.
There are three different positions that qualify as word boundaries:
- At string start, if the first string character is a word character
\w. - Between two characters in the string, where one is a word character
\wand the other is not. - At string end, if the last string character is a word character
\w.
For instance, regexp \bJava\b will be found in Hello, Java!, where Java is a standalone word, but not in Hello, JavaScript!.
alert( "Hello, Java!".match(/\bJava\b/) ); // Java alert( "Hello, JavaScript!".match(/\bJava\b/) ); // null
In the string Hello, Java! following positions correspond to \b:
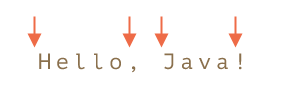
So, it matches the pattern \bHello\b, because:
- At the beginning of the string matches the first test
\b. - Then matches the word
Hello. - Then the test
\bmatches again, as we’re betweenoand a comma.
So the pattern \bHello\b would match, but not \bHell\b (because there’s no word boundary after l) and not Java!\b (because the exclamation sign is not a wordly character \w, so there’s no word boundary after it).
alert( "Hello, Java!".match(/\bHello\b/) ); // Hello alert( "Hello, Java!".match(/\bJava\b/) ); // Java alert( "Hello, Java!".match(/\bHell\b/) ); // null (no match) alert( "Hello, Java!".match(/\bJava!\b/) ); // null (no match)
We can use \b not only with words, but with digits as well.
For example, the pattern \b\d\d\b looks for standalone 2-digit numbers. In other words, it looks for 2-digit numbers that are surrounded by characters different from \w, such as spaces or punctuation (or text start/end).
alert( "1 23 456 78".match(/\b\d\d\b/g) ); // 23,78 alert( "12,34,56".match(/\b\d\d\b/g) ); // 12,34,56
Word boundary \b doesn’t work for non-latin alphabets
The word boundary test \b checks that there should be \w on the one side from the position and “not \w” – on the other side.
But \w means a latin letter a-z (or a digit or an underscore), so the test doesn’t work for other characters, e.g. cyrillic letters or hieroglyphs.