
Table of Contents
- 1. Các Collectors được xây dựng sẵn (build-in)
- 1.1. Collectors.toList()
- 1.2. Collectors.toSet()
- 1.3. Collectors.toCollection()
- 1.4. Collectors.toMap()
- 1.5. Collectors.collectingAndThen()
- 1.6. Collectors.joining()
- 1.7. Collectors.counting()
- 1.8. Collectors.summarizingDouble/Long/Int()
- 1.9. Collectors.averagingDouble/Long/Int()
- 1.10. Collectors.summingDouble/Long/Int()
- 1.11. Collectors.maxBy()/ Collectors.minBy()
- 1.12. Collectors.groupingBy()
- 1.13. Collectors.partitioningBy()
- 1.14. Collectors.reducing()
- 2. Custom Collectors
Stream.collect() là một trong các phương thức đầu cuối (terminal operation) của Stream API trong Java 8. Nó cho phép thực hiện các thao tác có thể thay đổi trên các phần tử được lưu giữ trong Stream. Chẳng hạn như: chuyển các phần tử sang một số cấu trúc dữ liệu khác, áp dụng một số logic bổ sung, tính toán, …
Lớp Java Collectors cung cấp nhiều phương thức khác nhau để xử lý các phần tử của Stream API. Chẳng hạn như:
- Collectors.toList()
- Collectos.toSet()
- Collectors.toMap()
- …
Trong bài viết này, tôi sẽ giới thiệu với các phương thức được xây dựng sẵn trong lớp Collectors và cách tạo, sử dụng một Custom Collectors.
1. Các Collectors được xây dựng sẵn (build-in)
Các Collectors được xây dựng sẵn trong lớp java.util.stream.Collectors.*
Trong phần tiếp theo của bài viết, chúng ta sẽ lần lượt tìm hiểu cách sử dụng từng phương thức trong lớp Collectors.
1.1. Collectors.toList()
Collectors.toList() : có thể được sử dụng để thu thập tất cả các phần tử Stream vào một List (kết quả luôn là ArrayList).
Ví dụ:
List<String> result = list.stream().collect(Collectors.toList());
1.2. Collectors.toSet()
Collectors.toSet() : có thể được sử dụng để thu thập tất cả các phần tử Stream vào một Set (kết quả luôn là HashSet).
Ví dụ:
List<String> result = list.stream().collect(Collectors.toSet());
1.3. Collectors.toCollection()
Khi sử dụng Collectors.toSet() và Collectors.toList(), bạn không thể xác định bất kỳ lớp cài đặt cụ thể nào của chúng như LinkedList, LinkedHashSet, TreeSet, … Nếu muốn sử dụng lớp cài đặt cụ thể, chúng ta cần phải sử dụng phương thức Collectors.toCollection(c) , với Collection được cung cấp tương ứng.
Ví dụ:
List<String> result = list.stream().collect(Collectors.toCollection(LinkedList::new));
1.4. Collectors.toMap()
Collectors.toMap() : có thể được sử dụng để thu thập tất cả các phần tử Stream vào một Map.
Cú pháp:
public static Collector<T, ?, M> toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper,
BinaryOperator<U> mergeFunction,
Supplier<M> mapSupplier) {}
Trong đó:
- keyMapper : là một Function<T, R> được sử dụng để trích xuất một khóa (key) từ một phần tử Stream.
- valueMapper : là một Function<T, R> được sử dụng để trích xuất một giá trị (value) được liên kết với một khóa (key) đã cho.
- mergeFunction : được sử dụng để giải quyết xung đột giữa các giá trị được liên kết với cùng một khóa. Tham số này không bắt buộc. Tuy nhiên, nếu trong danh sách có key trùng, nó sẽ throw một ngoại lệ IllegalStateException.
- mapSupplier : là một Supplier trả về một instance của Map mới, rỗng, trong đó kết quả sẽ được chèn vào. Tham số này không bắt buộc, mặc định là HashMap.
Ví dụ 1:
List<String> list = Arrays.asList("Java", "C++", "C#", "PHP");
Map<String, Integer> result = list.stream().collect(Collectors.toMap(Function.identity(), String::length));
// => {C#=2, Java=4, C++=3, PHP=3}
Function.identity() : là một phương thức tiện ích để xác định đối số và kết quả trả về cùng một giá trị.
Đôi khi trong danh sách các phần tử khi chuyển sang Map có các phần tử trùng key, khi đó chúng ta cần truyền vào đối số thứ 3 của Collectors.toMap() một BinaryOperator để giải quyết vấn đề này.
Ví dụ 2:
package com.maixuanviet.collectors;
import java.util.Arrays;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
class Student {
private String name;
private Integer score;
public Student(String name, int score) {
this.name = name;
this.score = score;
}
public String getName() {
return name;
}
public Integer getScore() {
return score;
}
}
public class CollectorsExample2 {
public static void main(String[] args) {
List<Student> students = Arrays.asList( //
new Student("B", 70), //
new Student("A", 80), //
new Student("C", 75), //
new Student("A", 100) //
);
// Resolve collisions between values associated with the same key
Map<String, Integer> result1 = students.stream().collect( //
Collectors.toMap(Student::getName, Student::getScore, //
(s1, s2) -> (s1 > s2 ? s1 : s2) // BinaryOperator
));
System.out.println("result1 : " + result1);
// Identify the instance of LinkedHashMap
Map<String, Integer> result2 = students.stream().collect( //
Collectors.toMap(Student::getName, Student::getScore, //
(s1, s2) -> (s1 > s2 ? s1 : s2), // BinaryOperator
LinkedHashMap::new // Supplier
));
System.out.println("result2 : " + result2);
}
}
Output của chương trình trên:
result1 : {A=100, B=70, C=75}
result2 : {B=70, A=100, C=75}
1.5. Collectors.collectingAndThen()
Collectors.collectingAndThen() là một bộ thu thập đặc biệt cho phép thực hiện một hành động khác ngay lập tức sau khi thu thập kết thúc.
Ví dụ:
List<String> list = Arrays.asList("Java", "C++", "C#", "PHP");
List<String> result5 = list.stream().collect(
Collectors.collectingAndThen(Collectors.toList(), x -> x.subList(0, 2)));
// => [Java, C++]
1.6. Collectors.joining()
Collectors.joining() : có thể được sử dụng join các phần tử Stream<String>.
Cú pháp:
public static Collector<CharSequence, ?, String> joining(CharSequence delimiter,
CharSequence prefix,
CharSequence suffix) {}
Trong đó:
- delimiter : chuỗi ký tự phân tách các phần tử.
- prefix : chuỗi ký tự được thêm vào đầu kết quả.
- suffix : chuỗi ký tự được thêm vào cuối kết quả.
Ví dụ:
List<String> list = Arrays.asList("Java", "C++", "C#", "PHP");
String result6 = list.stream().collect(Collectors.joining());
// => JavaC++C#PHP
String result7 = list.stream().collect(Collectors.joining(", "));
// => Java, C++, C#, PHP
String result8 = list.stream().collect(Collectors.joining(" ", "PRE-", "-POST"));
// => PRE-Java C++ C# PHP-POST
1.7. Collectors.counting()
Collectors.counting() : được sử dụng để đếm các phần tử trong Stream.
Ví dụ:
List<String> list = Arrays.asList("Java", "C++", "C#", "PHP");
Long result9 = list.stream().collect(Collectors.counting()); // => 4
1.8. Collectors.summarizingDouble/Long/Int()
Collectors.summarizingDouble/Long/Int() : trả về một lớp đặc biệt chứa thông tin thống kê về dữ liệu số trong Stream các phần tử được trích xuất.
Ví dụ:
List<String> list = Arrays.asList("Java", "C++", "C#", "PHP");
IntSummaryStatistics result10 = list.stream().collect(Collectors.summarizingInt(String::length));
// => IntSummaryStatistics{count=4, sum=12, min=2, average=3.000000, max=4}
1.9. Collectors.averagingDouble/Long/Int()
Collectors.averagingDouble/Long/Int() : trả về giá trị trung bình của các phần tử.
Ví dụ:
Double result = list.stream().collect(Collectors.averagingDouble(String::length));
1.10. Collectors.summingDouble/Long/Int()
Collectors.summingDouble/Long/Int() : trả về giá trị tổng của các phần tử.
Ví dụ:
Double result = list.stream().collect(Collectors.summingDouble(String::length));
1.11. Collectors.maxBy()/ Collectors.minBy()
Collectors.maxBy() / Collectors.minBy() : trả về giá trị lớn nhất/ nhỏ nhất của một Stream theo bộ Comparator được cung cấp.
Ví dụ:
Optional<String> result = list.stream().collect(Collectors.maxBy(Comparator.naturalOrder())); // => PHP Optional<String> result = list.stream().collect(Collectors.minBy(Comparator.naturalOrder())); // => C#
1.12. Collectors.groupingBy()
Collectors.groupingBy() : được sử dụng để nhóm các đối tượng theo một số thuộc tính và lưu trữ các kết quả trong một Map.
Ví dụ:
package com.maixuanviet.collectors;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.stream.Collectors;
class Book {
private Integer id;
private String title;
private Integer cagegoryId;
public Book(Integer id, String title, Integer cagegoryId) {
super();
this.id = id;
this.title = title;
this.cagegoryId = cagegoryId;
}
public Integer getId() {
return id;
}
public String getTitle() {
return title;
}
public Integer getCagegoryId() {
return cagegoryId;
}
@Override
public String toString() {
return "Book [id=" + id + ", title=" + title + ", cagegoryId=" + cagegoryId + "]";
}
}
public class CollectorsExample3 {
public static void main(String[] args) {
List<Book> books = Arrays.asList( //
new Book(1, "A", 1), //
new Book(2, "B", 1), //
new Book(3, "C", 2), //
new Book(4, "D", 3), //
new Book(5, "E", 1) //
);
Map<Integer, Set<Book>> result = books.stream()
.collect(Collectors.groupingBy(Book::getCagegoryId, Collectors.toSet()));
result.forEach((catId, booksInCat) -> System.out.println("Category " + catId + " : " + booksInCat.size()));
}
}
Output của chương trình trên:
Category 1 : 3 Category 2 : 1 Category 3 : 1
1.13. Collectors.partitioningBy()
Collectors.partitioningBy() : là một trường hợp đặc biệt của Collectors.groupingBy() chấp nhận một Predicate và thu thập các phần tử của Stream vào một Map với các giá trị Boolean như khóa và Collection như giá trị.
- Key = true, là một tập hợp các phần tử phù hợp với Predicate đã cho
- Key = false, là một tập hợp các phần tử không khớp với Predicate đã cho.
Ví dụ:
Map<Boolean, Set<Book>> partitioningBy = books.stream()
.collect(Collectors.partitioningBy(b -> b.getCagegoryId() > 2, Collectors.toSet()));
System.out.println(partitioningBy);
Output của chương trình:
{
false=[Book [id=3, title=C, cagegoryId=2],
Book [id=2, title=B, cagegoryId=1],
Book [id=1, title=A, cagegoryId=1],
Book [id=5, title=E, cagegoryId=1]],
true=[Book [id=4, title=D, cagegoryId=3]]
}
1.14. Collectors.reducing()
Collectors.reducing() : thực hiện giảm các phần tử đầu vào của nó trong một BinaryOperator được chỉ định.
Cú pháp:
public static <T> Collector<T,?,T> reducing(T identity, BinaryOperator<T> op) {}
public static <T> Collector<T, ?, Optional<T>> reducing(BinaryOperator<T> op) {}
Trong đó:
- identity : giá trị khởi tạo để thực hiện reduction (cũng là giá trị được trả về khi không có phần tử đầu vào).
- op : một BinaryOperator<T> được sử dụng để giảm các phần tử đầu vào.
Ví dụ: Trong ví dụ bên dưới chúng ta sẽ sử dụng reducing() để tìm nhân viên lớn tuổi nhất theo từng company, tính tổng lương phải trả cho tất cả nhân viên.
package com.maixuanviet.collectors;
import java.util.Arrays;
import java.util.Comparator;
import java.util.List;
import java.util.Map;
import java.util.Optional;
import java.util.function.BinaryOperator;
import java.util.stream.Collectors;
class Employee {
private String name;
private Integer age;
private String companyName;
private Integer salary;
public Employee(String name, Integer age, String companyName, Integer salary) {
this.name = name;
this.age = age;
this.companyName = companyName;
this.salary = salary;
}
public String getName() {
return name;
}
public Integer getAge() {
return age;
}
public String getCompanyName() {
return companyName;
}
public Integer getSalary() {
return salary;
}
}
public class CollectorsExample4 {
public static void main(String[] args) {
List<Employee> list = Arrays.asList( //
new Employee("Emp1", 22, "A", 50), //
new Employee("Emp2", 23, "A", 60), //
new Employee("Emp3", 22, "B", 40), //
new Employee("Emp4", 21, "B", 70) //
);
// Find employees with the maximum age of each company
Comparator<Employee> ageComparator = Comparator.comparing(Employee::getAge);
Map<String, Optional<Employee>> map = list.stream().collect(
Collectors.groupingBy(Employee::getCompanyName,
Collectors.reducing(BinaryOperator.maxBy(ageComparator))));
map.forEach((k, v) -> System.out.println(
"Company: " + k +
", Age: " + ((Optional<Employee>) v).get().getAge() +
", Name: " + ((Optional<Employee>) v).get().getName()));
// Summary salary
Integer bonus = 30;
Integer totalSalaryExpense = list.stream()
.map(emp -> emp.getSalary())
.reduce(bonus, (a, b) -> a + b);
System.out.println("Total salary expense: " + totalSalaryExpense);
}
}
Ouput của chương trình trên:
Company: A, Age: 23, Name: Emp2 Company: B, Age: 22, Name: Emp3 Total salary expense: 250
2. Custom Collectors
Mỗi static method trong lớp Collectors đều trả về một object kiểu Collector. Collector là một interface được khai báo trong java.util.stream.Collector.
Hãy xem sơ đồ sau:
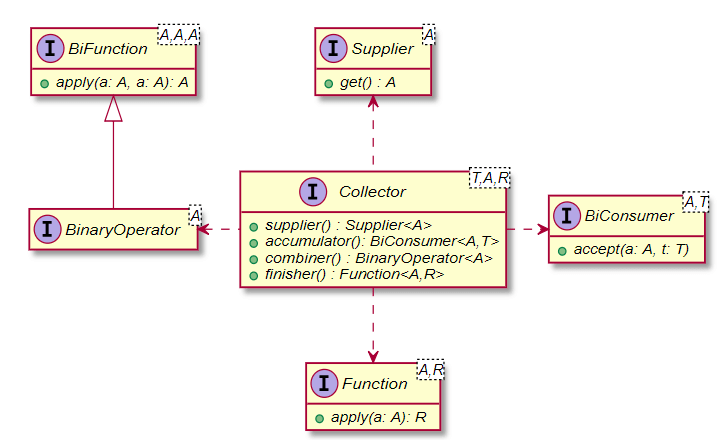
Các Generic type của interface Collector<T, A, R>:
- T : kiểu dữ liệu của phần tử trong Stream
- A : kiểu dữ liệu được sử dụng để giữ một phần kết quả của hoạt động thu thập.
- R : kiểu dữ liệu của kết quả thu thập được (collect).
Có 4 interface liên quan:
- Supplier : biểu diễn một operation không có đầu vào và đầu ra là 1 kết quả nào đó.
- BiConsumer : biểu diễn một operation có 2 biến đầu vào nhưng đầu ra không có gì.
- Function : Biểu diễn một hàm có 1 biến đầu vào và đầu ra là 1 kết quả nào đó.
- BinaryOperator : biểu diễn một operation có đầu vào là 2 toán tử cùng loại (same type), kết quả cũng cùng kiểu như đối số. Đây là một trường hợp của BiFunction khi mà toán tử và kết quả có cùng kiểu (type).
Các phương thức được yêu cầu bởi interface Collector:
- supplier() : có vai trò khởi tạo result container.
- accumulator() : lưu trữ các phần tử vào result container.
- combiner() : kết hợp 2 result container thành 1.
- finisher() : thực thi final transform cho container (nếu được yêu cầu).
- characteristics() : được sử dụng để cung cấp Stream với một số thông tin bổ sung sẽ được sử dụng cho các tối ưu hóa nội bộ. Ví dụ như trong trường hợp chúng ta không chú ý đến thứ tự các phần tử trong một Set, có thể sử dụng Characteristics.UNORDERED.
Các Characteristics được hỗ trợ:
- CONCURRENT : đặc điểm này có nghĩa là đối tượng accumulator() được trả về bởi suppier().get() có thể được thay đổi từ nhiều Thread đồng thời.
- UNORDERED : đặc điểm này có nghĩa là hàm được trả về bởi finisher() không đảm bảo thứ tự của các phần tử trong Stream. Ví dụ Collectors.toSet() có các đặc điểm này vì kết quả là Set không đảm bảo thứ tự của các phần tử của Stream. Đặc điểm này chủ yếu hữu ích khi làm việc với các luồng song song. Bộ thu thập UNORDERED cho phép tối ưu hóa nhiều hơn được thực hiện trong quá trình tách luồng thành các phần.
- IDENTITY_FINISH : đặc điểm này có nghĩa là hàm được trả về bởi finisher() là identity() và chúng ta có thể cast đối tượng accumulator() thẳng đến kiểu kết quả (R), bỏ qua finisher().
2.1. Tạo Collector kế thừa từ interface Collector
public interface Collector<T, A, R> {
Supplier<A> supplier();
BiConsumer<A,T> accumulator();
BinaryOperator<A> combiner();
Function<A,R> finisher();
Set<Characteristics> characteristics();
}
Ví dụ tạo một ProductCollector để đếm số lượng Product theo từng loại PRODUCT_TYPE dựa vào danh sách được cung cấp.
package com.maixuanviet.collectors;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.function.BiConsumer;
import java.util.function.BinaryOperator;
import java.util.function.Function;
import java.util.function.Supplier;
import java.util.stream.Collector;
enum PRODUCT_TYPE {
LAPTOP, SMART_PHONE, TABLET
}
class Product {
private Integer id;
private String name;
private PRODUCT_TYPE productType;
public Product(Integer id, String name, PRODUCT_TYPE productType) {
super();
this.id = id;
this.name = name;
this.productType = productType;
}
public Integer getId() {
return id;
}
public String getName() {
return name;
}
public PRODUCT_TYPE getProductType() {
return productType;
}
@Override
public String toString() {
return "Product [id=" + id + ", name=" + name + ", productType=" + productType + "]";
}
}
class ProductCollector implements Collector<Product, Map<PRODUCT_TYPE, List<Product>>, Map<PRODUCT_TYPE, Integer>> {
@Override
public Supplier<Map<PRODUCT_TYPE, List<Product>>> supplier() {
return HashMap::new;
}
@Override
public BiConsumer<Map<PRODUCT_TYPE, List<Product>>, Product> accumulator() {
return (map, product) -> {
List<Product> products;
if (map.get(product.getProductType()) == null) {
products = new ArrayList<>();
} else {
products = map.get(product.getProductType());
}
products.add(product);
map.put(product.getProductType(), products);
};
}
@Override
public BinaryOperator<Map<PRODUCT_TYPE, List<Product>>> combiner() {
return (left, right) -> {
left.putAll(right);
return left;
};
}
@Override
public Function<Map<PRODUCT_TYPE, List<Product>>, Map<PRODUCT_TYPE, Integer>> finisher() {
return (map) -> {
final Map<PRODUCT_TYPE, Integer> res = new HashMap<>();
for (Map.Entry<PRODUCT_TYPE, List<Product>> entry : map.entrySet()) {
res.put(entry.getKey(), entry.getValue().size());
}
return res;
};
}
@Override
public Set<Characteristics> characteristics() {
return Collections.singleton(Characteristics.UNORDERED);
}
}
public class CollectorsExample5 {
public static void main(String[] args) {
List<Product> products = new ArrayList<>();
products.add(new Product(1, "Dell", PRODUCT_TYPE.LAPTOP));
products.add(new Product(2, "Asus", PRODUCT_TYPE.LAPTOP));
products.add(new Product(3, "Acer", PRODUCT_TYPE.LAPTOP));
products.add(new Product(4, "HP", PRODUCT_TYPE.LAPTOP));
products.add(new Product(5, "iPhone", PRODUCT_TYPE.SMART_PHONE));
products.add(new Product(6, "Samsung", PRODUCT_TYPE.SMART_PHONE));
products.add(new Product(7, "Sony", PRODUCT_TYPE.SMART_PHONE));
products.add(new Product(8, "iPad", PRODUCT_TYPE.TABLET));
products.add(new Product(9, "Samsung Galaxy", PRODUCT_TYPE.TABLET));
ProductCollector productCollector = new ProductCollector();
Map<PRODUCT_TYPE, Integer> result = products.stream().collect(productCollector);
System.out.println(result);
}
}
Output của chương trình trên:
{LAPTOP=4, SMART_PHONE=3, TABLET=2}
2.2. Sử dụng Collector.of()
Để có thể tạo custom Collector, chúng ta phải cài đặt các phương thức của interface Collector. Tuy nhiên, thay vì cài đặt interface theo cách truyền thống, chúng ta sẽ sử dụng phương thức static Collector.of() để tạo custom Collector.
Cú pháp:
Collector.of( supplier, accumulator, combiner, finisher, Collector.Characteristics.CONCURRENT, Collector.Characteristics.IDENTITY_FINISH, // ... );
Ví dụ: lớp ProductCollector ở trên có thể được viết lại như sau:
Collector<Product, // T
Map<PRODUCT_TYPE, // A
List<Product>>, Map<PRODUCT_TYPE, Integer>> // R
productCollector2 = Collector.of( //
HashMap::new, // supplier
(map, product) -> { // accumulator
List<Product> list;
if (map.get(product.getProductType()) == null) {
list = new ArrayList<>();
} else {
list = map.get(product.getProductType());
}
list.add(product);
map.put(product.getProductType(), list);
}, (left, right) -> { // combiner
left.putAll(right);
return left;
}, (map) -> { // finisher
final Map<PRODUCT_TYPE, Integer> res = new HashMap<>();
for (Map.Entry<PRODUCT_TYPE, List<Product>> entry : map.entrySet()) {
res.put(entry.getKey(), entry.getValue().size());
}
return res;
}, Collector.Characteristics.UNORDERED // characteristics
);
Map<PRODUCT_TYPE, Integer> result2 = products.stream().collect(productCollector2);
System.out.println(result2);
Output của chương trình trên:
{LAPTOP=4, SMART_PHONE=3, TABLET=2}