
Table of Contents
- 1. A Little Bit Of History
- 2. Architectural Concerns
- 3. Example Application
- 4. Conclusion
Web applications are everywhere. There is no official definition, but we’ve made the distinction: web applications are highly interactive, dynamic and performant, while websites are informational and less transient. This very rough categorization provides us with a starting point, from which to apply development and design patterns.
Web applications are everywhere. There is no official definition, but we’ve made the distinction: web applications are highly interactive, dynamic and performant, while websites are informational and less transient. This very rough categorization provides us with a starting point, from which to apply development and design patterns.

These patterns are often established through a different look at the mainstream techniques, a paradigm shift, convergence with an external concept, or just a better implementation. Universal web applications are one such pattern.
Universality, sometimes called “isomorphism”, refers to ability to run nearly the same code on both client and server – a concept that was born out of the trials and tribulations in the past of creating applications on the web, availability of new technologies, and the ever-growing complexity of developing and maintaining these applications.
These applications, as well as drawbacks and benefits in their development and maintenance, are the topic of this article. By the end of it we will have discussed:
- a short history of web applications
- client-side and server-side rendering
- universal web applications’ structure and implementation
In addition, we will go through a lot of code, progressively building an application, or rather a sequence of evolving applications. These applications will attempt to illustrate concepts, problems and decisions made along the way. Enjoy!
1. A Little Bit Of History
“Those who don’t know history are destined to repeat it.”
Keeping in mind the cliché above, and before diving into universal web applications, it would suit us well to go over their journey and discuss the challenges and triumphs experienced along the way.
1.1. The age of static pages
The web, everyone’s favorite medium to find celebrity gossip and cat pictures, was designed as a linked information system. In other words, a web of interconnected hypertext documents, connected via hyperlinks. These documents were identified and located by a URL and retrieved by invoking the only HTTP method in existence: GET. The response, an HTML file, was then rendered in an appropriate application, usually a browser.
There was also Gopher, which I am trying to forget.
The HTTP protocol was created as a request/response protocol for client/server communication. It was the server’s responsibility to supply a resource corresponding to the requested URL; initially, most of the resources were static HTML files or, at best, images.
It was a simpler time.
The introduction of JavaScript in 1995 and Flash a year later, as well as the popularization of DHTML brought in a lot of flair and some functionality to otherwise dull text documents. The interactive web was born in all its blinking glory.
Static pages were relatively simple and quick to develop, easy to deploy and cheap to host; they were equally suitable for complex news sites or a couple of simple pages for beer bottle aficionados (yes, that’s a thing, of course). Such simplicity and ubiquity, however, are what possibly became the undoing of the static page – the sea of information became too hard to navigate, identify and sift through. The demand for personalized, dynamic and up-to-date content grew together with the web.
Static pages were going the way of the dodo.
1.2. Everyone was server scripting…
It was now clear that HTML content had to be created dynamically and there was just the tool for it: CGI.
The common gateway interface (CGI) is a standard way for web servers to interact with programs installed on the server’s machine. These programs (scripts, commonly placed under a designated folder called cgi-bin) are executed within the operating system the server is installed on; which is to say they can be written in almost any programming language in existence.
Historically, one of the most prominent places in CGI scripting belongs to Perl, a universal purpose language installed on almost all *nix machines. Perl had been around for almost 10 years at the time the web came a-calling and it was a convenient choice for the first makeshift web developers – they got to use the language and the tools they already knew.
Yes, there was, and still is, Python. And yes, it is funny how many of the opponents of JavaScript being everywhere yearn for the web of old. Which was Perl everywhere.
And so, they set to write more or less sophisticated variations of this:
#!/usr/local/bin/perl print "Content-type: text/html\n\n"; print "<html>\n"; print "<head><title>Perl - Hello, world!</title></head>\n"; print "<body>\n"; print "<h1>Hello, world!</h1>\n"; print "</body>\n"; print "</html>\n";
I apologize for you having seen it.
While having a lot of positive features, and sometimes being confused with its more glamorous Hollywood cousin, CGI in its canonical form also suffered from several drawbacks, namely a necessity to invoke a new process for a script when a request needed to be served and to interpret that script. Solutions for these issues exist (e.g. FastCGI and writing scripts in compiled language like C/C++) but are not ideal.
More importantly, Perl was not designed to be a web development-oriented language. This resulted in an awkward experience for the developers, which was somewhat improved by various higher-level abstraction modules, like cgi.pm, but not nearly enough to prevent many of them from searching for greener pastures.
1.3. Server pages
One of these searches brought in PHP, initially a collection of CGI-related C binaries written to serve the needs of its creator, Rasmus Lerdorf, which evolved into a full-blown language.
Even in its earliest form, PHP allowed you to do something that was to become a common paradigm for most, if not all, similar server pages languages (JSP, for one): it allowed you to write your server-side code directly in the HTML, a marked improvement that allowed for a much better development workflow.
<!DOCTYPE html> <html> <head> <title>PHP - Hello, world!</title> </head> <body> <?php echo '<h1>Hello, world!</h1>'; ?> </body> </html>
The convenience of this was not lost on developers and, by extension, web server vendors. In addition to the still-existing ability to run PHP as CGI scripts, web servers began to implement various modules that would run PHP code in a container within the web server itself.
This allowed web developers to:
- write their code in high-level C-like languages
- use HTML files, sometimes ones that already existed, to enhance the application with dynamic functionality
- not worry about the minutiae of folders, files, scripts, permissions management, and so on
Throw in improved performance, due to not having to spend time on process/script warm-up, and PHP took the web by storm. By some accounts, during various times and at its peak, PHP was installed and used on nearly 10% of all servers on the web.
JavaServer Pages (JSP), an extension to Java servlets, was one of many to follow. The concept, of course, was very similar: web servers, through servlet container modules, allowed running JSP code within the server itself and provided an extensive set of management capabilities on top of them. JSP, however, had one additional selling point: it brought in the power of Java. Some publications called it “platform to build the Web upon, for serious programmers.” Whether you subscribe to that line of thinking or not, one thing is undeniable: JSP (along with Struts, Spring and other additions to the JEE stack) became the cornerstone of enterprise web applications development.
And there were more. ColdFusion, ASP.NET. Or JSF. The future looked bright for the server pages and their brethren.
1.4. Universal web applications?
The technologies and frameworks above are beyond having proved their worth. They are not without issues, though: spreading presentation logic between client and server, session and state management (back button anyone?), higher entry level for both companies and developers due to a more expensive setup and more demanding skill set requirements – all contribute to dynamic server pages not being the ideal solution.
Remember that trite line from before, on history and repeating it? Universal web applications repeat some history after learning from it.
Consider the main concepts:
- a common language to use on both client and server: JavaScript
- usage of a simple markup language: still HTML
- writing directives directly in HTML: any of dozens of template engines like Handlebars
- execution of scripts on server machine: Node, Express and a horde of other modules
All of these can be attributed to some past concepts and paradigms, which are now being revisited. Some of it may be due to our accumulated knowledge of how to use them properly. Some because they’ve made the evolutionary leap. And yet more because new tools and techniques allow the experience of using them to be less horrible.
Coincidentally, JavaScript fits all of the above.
There used to be a clear separation line: server pages and mechanisms handle routing, markup and content creation, while JavaScript handles all the silly enhancements to the delivered HTML.
Note: if you never composed your rollover buttons from (at least) two images and inline JavaScript, you haven’t lived.
Lately, improvements in browsers, standardization, tooling and infrastructure – specifically around JavaScript – ushered in a change in its role within the web applications development stack. It is, at this point, a common practice to create markup or content using JavaScript. Moreover, especially with Node inception in 2009, it is now routinely done on the server.
The line is shifting.
2. Architectural Concerns
Before we bask in the glory that are universal web applications, while leaving somewhat dusty, mothball-covered server pages behind, it is worthwhile to outline a number of concerns, possible solutions and common misconceptions.
While there are many more items to be taken into consideration when defining application architecture, performance, machine-friendliness and maintenance are to be our main focus.
2.1. Performance
There is no need to argue that performance affects the most important part of any application: the bottom line. Companies like Walmart, Amazon and Google reported clear connections between their revenue and the performance of their sites, and this connection holds true for smaller businesses as well.
I would go even further and say that perceived performance is more important than actual performance.
Perceived Performance
Among other things, performance deals with two important aspects: load time and interactivity. Both of these characteristics have objective clock-time (see links above) measures, but in many cases it is the subjective perception of them that matters.
Load time perception (in unofficial terms) measures how much time it takes for user to deem the page usable after interacting with it. Interactivity perception measures the time it takes for users to consider the interaction to be started and finished successfully.
Interactivity perception is usually altered on the UX level by some combination of client-side JavaScript and CSS, and thus lies somewhat outside the scope of this article, but load time perception can and should be affected by the manner in which you render and deliver your markup and content to user.
Computing Power
There is a relatively popular sentiment that today’s devices (both mobile and desktop) are powerful enough and have enough free CPU power and RAM to do all the heavy lifting of running a web application in the browser, including HTML construction and rendering. “Unauthorized” distributed computing, if you will.
This, of course, is a lazy approach.
Indeed, mobile devices get more powerful seemingly every day. They also run an ever increasing number of demanding applications, all of which consume RAM, CPU and battery. It is overly optimistic to assume that there is a lot to be had without affecting the usability of these devices.
Also there is an alleged corollary which claims that allowing millions of users to overload servers with HTML creation and rendering is expensive and a wasteful use of hardware. Considering it’s a near certainty that most applications do not have millions of users and the fact that Amazon cloud services and the like are relatively cheap these days, that’s a bit of a hypocritical statement.
When you precompile your templates, which is common advice, there should not be any significant difference between this approach and, for example, JSP. In addition, when concerns about JSP performance and scalability arise, they are regularly solved via deployment and topological solutions. Adding more nodes to your cluster is often considered a sound suggestion.
So, add more Nodes to your cluster.
I apologize for that as well.
2.2. Machine friendliness
We write our applications first and foremost for humans, but it is machines that consume them more and more often.
SEO And Machine Semantics
From Googlebot to Facebook crawler, machines consume our applications. Not to click on pretty buttons and navigate amazing menus – to get at our content. They do it for their owners’ benefit, naturally, but concerns like discoverability and search rank allow us, application creators, as well. They aid in exposing our applications to a larger audience, helping our bottom line.
The problem is that despite Google’s foggy claims, many machines can’t or aren’t willing to run JavaScript, affecting heavily our ability to move markup and content creation to the client. That is, provided we wanted to.
Aside from being (or not being) able to consume the actual content, machines are also limited in their ability to understand it. Various solutions, including microdata, JSON-LD and RDFa, were designed to standardize the way in which we can convey the semantic meaning of content to machines. All of these rely on HTML, or JSON-like structures in HTML, to carry the semantics and so, again, limit markup and content creation on the client.
Cue Skynet jokes.
In contrast to the pragmatic content consumers above, assistive technologies, like screen readers, are machines that want to click our buttons and need to navigate our menus, in order to allow humans using them to consume the content in an acceptable manner.
Thankfully, the situation here is better as this 2014 survey clearly shows that JavaScript is operational on an overwhelming majority of screen reader-enabled browsers. It still can be botched, sure, but not for the lack of ability to execute our excellent JavaScript code.
2.3. Maintenance
Single codebase*. One language. Similar development concepts. One effort!
If you factor in mobile development, a single application may be developed in three to four different ecosystems, which affects a company’s ability to maintain and develop web applications, both from technical and staffing standpoints.
Universal web applications, by their very nature, reduce that complexity.
Almost – as there are still things we haven’t transferred into JavaScript, like… I can’t think of one… Eureka! That’s it! CPU-bound computations!
3. Example Application
Finally!
As I’ve mentioned before, this isn’t a single all-encompassing application, rather a series of smaller ones, that evolve or in some cases mutate, one into another.
This setup, while perhaps less ideal for copy-and-pasting (see GitHub repository links below for that), should allow us to discuss issues and their solutions as they happen.
Working knowledge of React, React Router and ES6 is assumed and required.
3.1. Application structure
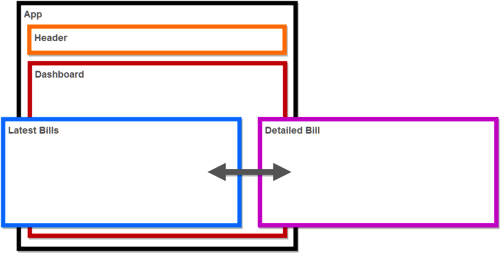
We are going to develop a very simple application that has two pages:
- list of all latest paid bills
- specific bill’s details (added in one of the later versions of the application)
Master–detail at its finest.
It will look, approximately, like this:
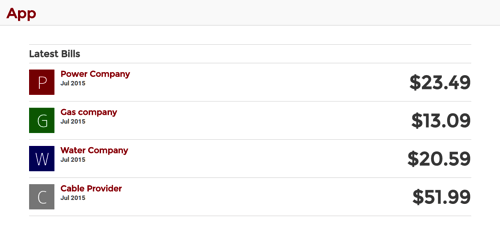
All the examples can be found (separated into branches) in this GitHub repository.
3.2. Technology stack
I am extremely excited by the latest advancements in tooling and JavaScript’s abilities as a language. Sure, not all additions are altogether welcome, but, from a pragmatic standpoint, the easier it is to write the code, the better.
So, the following will be the pillars of the development of our application:
- ES6: for all JavaScript code (I am not calling it ES2015, even if they paid me)
- Node + Express: as our web server platform
- Handlebars: for the server-side templating engine
- React, React Router and, less importantly, SCSS as the basis for our application’s presentation layer
- Gulp, Webpack for packaging; Babel for ES6 → ES5 transpiling; and BrowserSync for live reload across browsers during development
- ESLint for linting
There is a very fine balance to be struck between providing something that can be clearly presented in the format of an article and completeness of a technical solution. In an attempt to walk that line, some interesting items, like Webpack hot module replacement or Handlebars templates precompilation were left out, hopefully without taking anything from our ability to discuss the main topic at hand. Also, where possible, examples where abridged to preserve space. Full code can be found in the repository and its branches.
3.3. Simple, browser-only application
The application is in the same GitHub repository, under the simple branch.
This is where we start our journey toward universality bliss. A simple application (that doesn’t even have the second detailed bill page yet) that is the epitome of client-side rendering. There is no Flux, or Ajax API extraction (that is to come later), just simple React.
Setup
This will remain mostly the same through the evolution of our application.
Setup, Step 1: Handlebars Configuration
For simplicity’s sake, I’ve decided to deliver all HTML content, including pages that are essentially static, by rendering them from Handlebars templates. These pages, of course, can be cached just as well and allow for greater flexibility (and simplify our story too).
config-manager.js
Provides configuration for various Express-level features.
app.set('views', PATH.resolve(__dirname, ROOT, nconf.get('templateRoot')));
app.engine('hbs', HBS({
extname:'hbs',
defaultLayout:'main.hbs',
layoutsDir: PATH.resolve(__dirname, ROOT, nconf.get('templateLayouts'))
}));
app.set('view engine', 'hbs');
noconf is a configuration files management mechanism.
Setup, Step 2: Page Templates
Main layout:
main.hbs
<!DOCTYPE html>
<html lang="en">
<head>
<title>App</title>
<link rel="stylesheet" href="/assets/css/style.css">
</head>
<body>
</body>
{{{body}}}
<script src="//cdnjs.cloudflare.com/ajax/libs/react/0.14.2/react.js"></script>
<script src="//cdnjs.cloudflare.com/ajax/libs/react-router/1.0.0/ReactRouter.js"></script>
<script src="//cdnjs.cloudflare.com/ajax/libs/react/0.14.2/react-dom.js"></script>
<script src="//cdnjs.cloudflare.com/ajax/libs/history/1.12.6/History.js"></script>
</html>
and specific page content:
index.hbs
<div data-ui-role="content">{{{content}}}</div>
<script src="/assets/js/app.js" defer></script>
your code here
As can be seen, I’ve opted to consume third-party libraries from a CDN, instead of packaging them together with the application (or extracting them into a vendor bundle, using corresponding Webpack configuration). Between faster bundling and clear CDN benefits this made the most sense.
Generally, depending on economics, frequency and character of application updates, the application app.js file referenced in index.hbs above is also a candidate to be put onto CDN, like any other static resource.
Application Code
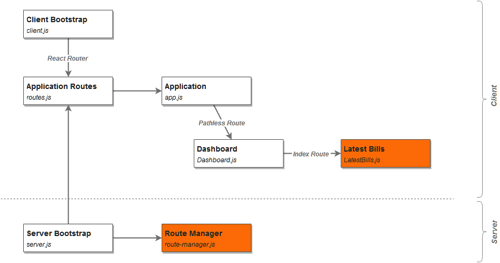
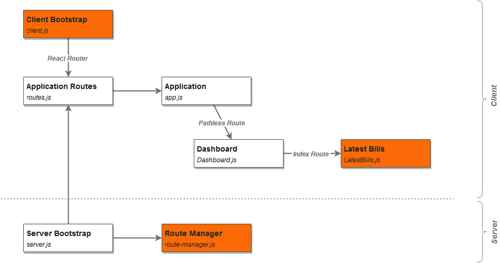
This incarnation of our application, like those to follow, uses React and React Router to render its UI. The implementation is fairly standard. The most important parts are described in the following diagram:
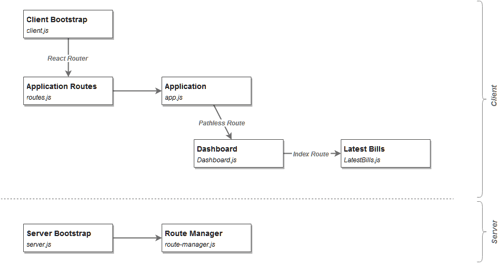
Application Code, Step 1: Server
In the repository you can see the entire setup, but for our purposes most of the relevant code is in the router-manager.js file, responsible for Express routes setup and data APIs.
There is a separate express.Router for both page and API routes.
router-manager.js
...
createPageRouter() {
const router = express.Router();
// respond with index page to ANY request
router.get('*', (req, res) => {
res.render('index');
});
return router;
},
createApiRouter(app) {
const router = express.Router();
router.get('/latest-bills', (req, res) => {
this.retrieveLatestBills((err, content) => {
if(!err) {
res.json(JSON.parse(content));
} else {
res.status(500).send();
}
});
});
return router;
}
...
Application Code, Step 2: Client
Note that in many cases less significant details, like CSS classes, are omitted for brevity.
client.js
...
import routes from './routes';
render((
<Router history={createHistory()}>
{routes}
</Router>
), document.querySelectorAll('[data-ui-role="content"]')[0]);
routes.js
...
export default (
<Route path="/" component={App}>
<Route component={Dashboard}>
<IndexRoute component={LatestBills}/>
</Route>
<Route path="*" component={NoMatch}/>
</Route>
);
The reason for using pathless Route (one that doesn’t have the path attribute) is to create a logical and visual container, without having it be a part of the Routes’ path. We’ll expand on this later in the article.
app.js
export default class App extends React.Component {
render() {
return (
<div>
<Header root={this.props.route.path}/>
{this.props.children}
</div>
);
}
}
Header.js
export default class Header extends React.Component {
render() {
return (
<header>
<h1>
<IndexLink to={this.props.root}>App</IndexLink>
</h1>
</header>
);
}
}
Dashboard.js
export default class Dashboard extends React.Component {
render() {
return (
<main>
{this.props.children}
</main>
);
}
}
LatestBills.js
export default class LatestBills extends React.Component {
constructor(props) {
super(props);
this.state = {items: []};
}
render() {
return (
<section>
<header><h3>Latest Bills</h3></header>
<section>
<List items={this.state.items} itemType={CompactBill}/>
</section>
</section>
);
}
componentDidMount() {
fetch('/api/latest-bills').then((response) => {
return response.json();
}).then((data) => {
this.setState({items: data.items});
}).catch((err) => {
throw new Error(err);
});
}
}
LatestBills component uses List and CompactBill pure components to construct its UI. Being able to seamlessly pass components to other components is one of the more subtle, overlooked and absolutely awesome features of React.
LatestBills, like the commonly accepted, albeit somewhat simplified pattern, issues an Ajax request in componentDidMount to populate its data.
CompactBill component looks like you would expect:
export default class CompactBill extends React.Component {
render() {
const data = this.props.data;
const price = `$${data.price}`;
return (
<div>
<img src={data.icon}/>
<div>
<h4>{data.vendor}</h4>
<span>{data.period}</span>
</div>
<span>{price}</span>
</div>
);
}
}
Analysis
The process of loading the application above may be schematically represented in the following manner:
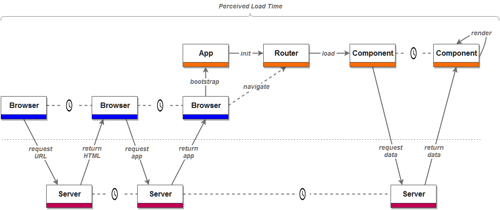
This is far from optimal, as the user has to wait, in many cases, for the entire HTML → JavaScript → data sequence to finish, in order to be able to use the application.
This depends on the nature of the application. In some cases parts of the application may be rendered and become usable before it is fully rendered. On the opposite side of the spectrum there are applications that, despite being fully rendered, are not yet interactive, as not all JavaScript and/or data has been retrieved.
While it may be improved by further optimization (the link serves as an excellent starting point), the improvements are still limited by data that you need to retrieve after the application code has been downloaded and parsed. This takes time and negatively impacts perceived performance.
Since the entire application is rendered in the browser using data brought in by Ajax, its machine-friendliness is questionable at best. There are measures you can take (like snapshotting), but they add more complexity and are prone to error.
We can do better.
3.4. Naive universal application
The application can be found in the simple+ssr branch.
The idea behind this version of the application is to:
- render HTML on the server, based on data necessary
- deliver the HTML to the browser
- send the data used to render the HTML to the browser as well
- allow React to resolve the necessary rerenders
- profit
Profit here means the ability to render and deliver friendly markup to machines and a quick response to the human user.
Setup
There is no change in the general setup of the application.
Application code
The structure remains the same, with some parts undergoing various changes.
3.4.1. Server
route-manager.js
// extend React Router RoutingContext
class AugmentedRoutingContext extends RoutingContext {
createElement(component, props) {
// inject additional props into the component to be created
const context = this.props.context;
return component == null ?
null : this.props.createElement(component, {...props, ...{context}});
}
};
const routeManager = Object.assign({}, baseManager, {
...
createPageRouter() {
const router = express.Router();
router.get('*', (req, res) => {
// match URL to our application's routes
match({routes, location: req.originalUrl}, (err, redirect, renderProps) => {
// we just retrieve latest bills, as it is the only one we have
this.retrieveLatestBills((err, data) => {
if(!err) {
// render the HTML
const html = this.render(renderProps, data);
// delive the HTML to the browser
res.render('index', {
content: html,
context: data
});
} else {
res.status(500).send();
}
});
});
});
return router;
},
...
render(renderProps, data) {
// create context to be passed down in additional props
const additionalProps = {context: JSON.parse(data)};
const html = renderToString(
<AugmentedRoutingContext {...renderProps} {...additionalProps}/>
);
return html;
}
});
This is where the bulk of the changes is. The process may be described as follows:
- match (and then completely disregard, for now) the URL to the application’s routes
- request the data for the latest bills
- when the data arrives, render the HTML using
renderToStringand send it to the browser - create context to be used in component’s rendering and attach it to the HTML above
Here, AugmentedRoutingContext allows us to inject data in all components, so that it is available to LatestBills during server rendering. It may not be efficient or pretty, but it means we don’t have to propagate the data through the entire component tree.
3.4.2. Client
There are only two changes:
index.hbs
<div data-ui-role="content">{{{content}}}</div>
<script>
window.APP_STATE = {{{context}}};
</script>
<script src="/assets/js/app.js" defer></script>
LatestBills.js
export default class LatestBills extends React.Component {
constructor(props) {
super(props);
this.state = this.props.context || process.APP_STATE || {items: []};
}
render() {
return (
<section>
<header><h3>Latest Bills</h3></header>
<section>
<List items={this.state.items} itemType={CompactBill}/>
</section>
</section>
);
}
// still retrieve data via AJAX, to update (if changed) the one received
// from the server in the initial load
componentDidMount() {
fetch('/api/latest-bills').then((response) => {
return response.json();
}).then((data) => {
this.setState({items: data.items});
}).catch((err) => {
throw new Error(err);
});
}
}
The data we used on the server to render the initial HTML needs to be passed to the browser. The reason for that is that in the browser, when our application is eventually downloaded and run, React needs to reconcile the HTML, attach event handlers and do all sorts of maintenance work. Data, used to render the application, is crucial to that, as it allows React to not touch parts that haven’t been changed when using the same data for reconciliation.
The simplest way to deliver the data is by injecting it into the HTML as a JSON string in a global (forgive me) variable using window.APP_STATE = {{{context}}};.
Now, the only thing that remains is to actually pass that data to the LatestBills component for React to consider, which is what these lines are doing:
constructor(props) {
super(props);
this.state = this.props.context || window.APP_STATE || {items: []};
}
Note that if we where to omit window.APP_STATE, we’d get the dreaded:
Warning: React attempted to reuse markup in a container but the checksum was invalid. This generally means that you are using server rendering and the markup generated on the server was not what the client was expecting…
indicating that React wasn’t able to reconcile and merge the data (since we didn’t give it any).
The interesting part about window is that on the server it works because of the || short-circuit evaluation. Despite window not existing on server, it is never evaluated, because we passed in the context via AugmentedRoutingContext which then became this.props.context.
3.4.3. Analysis
The process of delivering the application and its data to the user (both human and machine) is now changed:
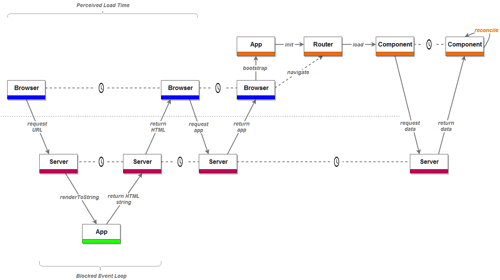
Look at that performance!
Before we start gleefully high-fiving each other and contemplate where to get an early lunch, consider the implications of the solution. We provided the application, in browser, with the data that was used to render it on the server, but the process is far from satisfactory.
Users, via the dark magic of link sharing, search engines and clicking those annoying browser buttons, do not always arrive at your application’s front door. They appear directly in its kitchen, expecting to see a hot kettle on the stove and cookies on the table. It’s up to you (well, the server) to understand what they expect to receive based on some external information on how they arrived there, as they… they do not speak.
The “do not speak” part of the forced sentence above refers to the fact that components should be as detached from routing logic as possible. This means that we do not couple the components with their corresponding routes. Thus, they can’t tell the server how they got there. It has to deduce that from the routes, hence the match({routes, location: req.originalUrl}, (… call.
Allegories aside, this means that in order to be able to piggyback the data onto the application’s HTML, some logic on the server would have to decide what data is needed and preferably attach only that data.
In our primitive application the decision of which data API to hit was very straightforward: we only have one. However, when the routes hit multiple components, each of which requires data to render, this quickly becomes a nightmare to code and maintain.
More importantly, implementing it would mean that you essentially rewrite your application presentation logic. On the server. Which negates one of the major reasons to have universal applications in the first place: a single, as DRY as possible, codebase.
The next logical question would be: “Why not let each component either receive props from its parent or retrieve data and then render itself, much like in the browser?” And herein lies one of the main hurdles! React’s renderToString (and renderToStaticMarkup) methods are, unfortunately, synchronous. That means, since most of the data retrieval mechanisms are asynchronous, that you can’t let components render themselves on server.
It simply wouldn’t work. The data is either lost, because no one waits for it:
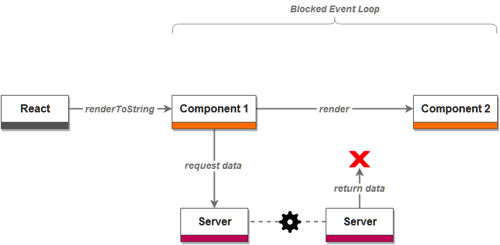
or it blocks the event loop:
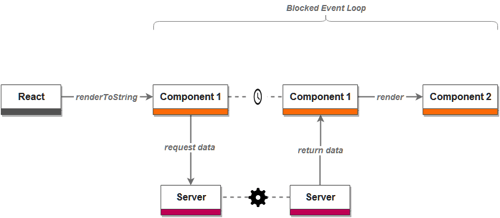
Event loop blocking (mentioned in brief in the diagrams above) is, of course, a problem. In this instance, the rendering is a CPU-bound operation, which for our application above, on my relatively decent machine, takes around 10ms on average. That’s time Node doesn’t use to serve other requests. We’ll get back to this topic toward the end of the article, as it is a universal issue for any server-rendering solution and not specific to this implementation or React.
We are getting closer, as concerns like SEO are being addressed, but the elusive universal web application is still not there.
3.5. A little less naive universal application
The application can be found in the simple+ssr+context branch.
Before moving on to greater challenges and more complex variations of the application, let’s rework the last example to make use of a relatively new (and still experimental) feature of React: Contexts.
This feature allows you to pass data to components from parents, without having to explicitly propagate it via props, which, as you can probably tell, is what we did with our AugmentedRoutingContext above.
So, let’s React-ify the previous effort a little bit.
Keep in mind that with great power and all that, this should be used judiciously.
Application code
The structure remains the same, with some parts undergoing various changes.
Server
The only change is in the render method:
route-manager.js
...
render(renderProps, data) {
const parsedData = JSON.parse(data);
let html = renderToString(
<ContextWrapper data={parsedData}>
<RoutingContext {...renderProps}/>
</ContextWrapper>
);
return html;
}
...
This is already much more React-ive approach, where the ContextWrapper component used above looks like this:
ContextWrapper.js
export default class ContextWrapper extends React.Component {
// exposes a property to be passed via the Context
static get childContextTypes() {
return {
data: React.PropTypes.object
};
}
// populates the property
getChildContext() {
return {
data: this.props.data
};
}
render() {
return this.props.children;
}
}
ContextWrapper defines the Context property type and provides a method that retrieves it. All that is left for the wrapped component to do is to declare its desire to consume the Context property via the contextTypes static property.
Notice that ES6 doesn’t have static properties, but allows us to define static methods, including getters (static get childContextTypes()) that will serve as properties instead.
The only component we currently have that consumes data is LatestBills, so we alter it to opt in to Context and change its constructor to not rely on window.APP_DATA and read its initial data from the Context instead.
LatestBills.js
...
static get contextTypes() {
return {
data: React.PropTypes.object
};
}
constructor(props, context) {
super(props, context);
this.state = context.data || {items: []};
}
...
Client
And what happens in the browser? We are going to use ContextWrapper in the same manner:
client.js
...
render((
<ContextWrapper data={window.APP_STATE}>
<Router history={createHistory()}>
{routes}
</Router>
</ContextWrapper>
), document.querySelectorAll('[data-ui-role="content"]')[0]);
Now, the only place in browser that has any dependency on the window.APP_STATE atrocity is in client.js. Small win.
3.6. More complex, but still naive, application
The application can be found in the simple+ssr+context+promise branch.
We are going to expand the application by adding another, without doubt highly anticipated, page: Detailed Bill.
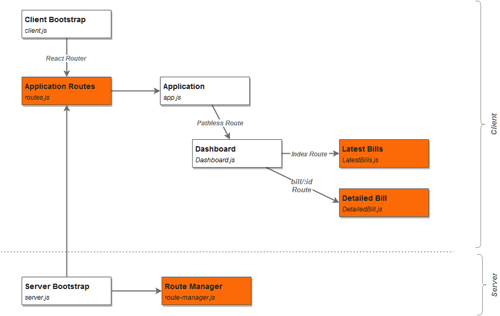
The new page looks similar to the following:

In addition, we will teach those components to talk. Basically, we are going to provide the server with some information about how and what data should be loaded to render the needed components.
Application Code
Server
route-manager.js
...
const routeManager = Object.assign({}, baseManager, {
...
createPageRouter() {
const router = express.Router();
router.get('*', (req, res) => {
// match routes to the URL
match({routes, location: req.originalUrl},
(err, redirectLocation, renderProps) => {
// each component carries a promise that retrieves its data
const {promises, components} = this.mapComponentsToPromises(
renderProps.components, renderProps.params);
// when all promises are resolved, process data
Promise.all(promises).then((values) => {
// create map of [component name -> component data]
const data = this.prepareData(values, components);
// render HTML
const html = this.render(data, renderProps);
// send HTML and the map to the browser
res.render('index', {
content: html,
context: JSON.stringify(data)
});
}).catch((err) => {
res.status(500).send(err);
});
});
});
return router;
},
// some components define a `requestData` static method that returns promise;
// skip the rest
mapComponentsToPromises(components, params) {
const filteredComponents = components.filter((Component) => {
return (typeof Component.requestData === 'function');
});
const promises = filteredComponents.map(function(Component) {
return Component.requestData(params, nconf.get('domain'));
});
return {promises, components: filteredComponents};
},
// create component name -> component data map
prepareData(values, components) {
const map = {};
values.forEach((value, index) => {
map[components[0].NAME] = value.data;
});
return map;
},
render(data, renderProps) {
let html = renderToString(
<ContextWrapper data={data}>
<RoutingContext {...renderProps}/>
</ContextWrapper>
);
return html;
},
...
createApiRouter(app) {
...
router.get('/bill/:id', (req, res) => {
const id = req.params.id;
this.retrieveDetailedBills((err, data) => {
if(!err) {
const billData = data.items.filter((item) => {
return item.id === id;
})[0];
res.json(billData);
} else {
res.status(500).send(err);
}
});
});
return router;
}
});
Data sanitation was skipped for brevity.
As you can see there are several things happening here:
- a new
/bill/:idAPI endpoint that returns specific bill’s detailed information is defined - all Route components that do not have
requestDatastatic method are filtered out requestData(that returns promise) for the remaining components is invoked and promises are kept- when all promises are fulfilled, we process the accumulated data and create a map of
name→datafor each component - each component provides a static
NAMEproperty - HTML is rendered and, along with the data, sent to the browser
The above is made possible because React Router provides the list of involved Routecomponents in renderProps.components property.
This approach allows us to achieve two main things:
- provide a hook for the server to use, on per-component basis, to retrieve only the data that component needs
- allow components to consume it later on in the browser, from the provided map
Client
A new Route component, Detailed Bill, is added to the routes configuration.
routes.js
export default (
<Route path="/" component={App}>
<Route component={Dashboard}>
<IndexRoute component={LatestBills}/>
<Route path="bill/:id" component={DetailedBill}/>
</Route>
<Route path="*" component={NoMatch}/>
</Route>
);
Now is the time, as promised, to dive a little into the pathless Dashboard route.
Pathless here, of course, means the lack of explicit path attribute on its definition:
<Route component={Dashboard}>…</Route>.
The idea is simple: Dashboard component contains some common (for all nested components) functionality and markup, and should be loaded by default, as should LatestBills component.
React Router provides a way of dealing with these situations:
If (path) left undefined, the router will try to match the child routes.
Thus loading / resolves Dashboard and then attempts to resolve its children, namely LatestBill, while loading /bill/1234 also resolves Dashboard and then resolves DetailedBill instead.
That being out of the way, let’s move on to the implementation part.
In the DetailedBill component below, note the retrieval process of the initial data from the map. Map is still, as before, propagated via React Context. Again, note the static getter methods, serving as static properties.
DetailedBill.js
export default class DetailedBill extends React.Component {
static get NAME() {
return 'DetailedBill';
}
static get contextTypes() {
return {
data: React.PropTypes.object
};
}
static requestData(params, domain = ’) {
return axios.get(`${domain}/api/bill/${params.id}`);
}
constructor(props, context) {
super(props, context);
// get THIS component's data from the provided map
this.state = context.data[DetailedBill.NAME] || {};
}
render() {
const price = `$${this.state.price}`;
return (
<section>
<header><h3>Bill Details</h3></header>
<section>
<div>
<img src={this.state.icon}/>
<div>
<h4>{this.state.vendor}</h4>
<span>{this.state.period}</span>
<hr/>
<span>
<span>Paid using: </span>
<span>{this.state.paymeans}</span>
</span>
</div>
<span>{price}</span>
</div>
</section>
</section>
);
}
componentDidMount() {
this.constructor.requestData(this.props.params).then((response) => {
this.setState(response.data);
}).catch((err) => {
console.log(err);
});
}
}
Similar change is done to the LatestBills component, whereas render method remained unchanged and thus has been skipped:
LatestBills.js
export default class LatestBills extends React.Component {
static get NAME() {
return 'LatestBills';
}
static get contextTypes() {
return {
data: React.PropTypes.object
};
}
static requestData(params, domain = ’) {
return axios.get(`${domain}/api/latest-bills`);
}
constructor(props, context) {
super(props, context);
this.state = context.data[LatestBills.NAME] || {items: []};
}
...
componentDidMount() {
this.constructor.requestData().then((response) => {
this.setState(response.data);
}).catch((err) => {
console.log(err);
});
}
}
Analysis
This attempt allowed us to discover a paradigm that gets us closer to the ultimate universal web application – the ability to convey to the server which data the specific set of routes that construct the request URL requires.
So, in our imaginary universal web application checklist we now have:
- ability to render our application on server and client, using the same code
- ability to translate URL to application components to be rendered
- ability to deduce the necessary data to render these components
- ability to reconcile the data used on server with the client
What we still lack is:
- ability to asynchronously render the application on server
- ability to reliably control the event loop blocking
One important point to consider is that all the data retrieval logic we delegated to the server pertains only to Route components, because any inner components, like CompactBill in our application, are left to their own devices. Since they are not passed as part of renderProps (in renderProps.components property), we won’t be able to invoke their corresponding data retrieval methods.
3.7. A note on data loading
While a more in-depth discussion of universal data loading is a topic for a separate article, it is worth pausing here for a moment and address the issue that comes with it.
The decision, mentioned above, to limit data to Route components only is an important and non-voluntary one. React doesn’t provide, currently, a built-in, structured way of retrieving data on the server without either forfeiting performance and availability (by blocking on data retrieval) or compromising on depth from which the pure components start. That is because both renderToString and renderToStaticMarkup methods, as was mentioned before, are synchronous.
Any component that is not a Route component, must be pure (as in – expecting to receive data via props) for the purposes of server-side rendering.
One could argue that there is a method to the madness, perhaps. In most cases, you’d be wise to detach your data retrieval logic, even simple API calls, from as many components as you can, striving for more pure components, as these are easier to develop, test and maintain.
Nevertheless, such an approach may not suit all applications, and when you consider that data fetching may rely on a much more complex inter-dependent mechanism, we’d be wise to find a more robust solution.
As an example of such a solution (or beginnings of it), consider HTML streaming – an alternative to React’s native renderToString, where the result is streamed (along with the surrounding HTML) to the client, instead of blocking. react-dom-stream is one of the possible implementations.
3.8. Flux universal application
The application can be found in the flux+ssr+context+promise branch.
At this point I can literally hear rumblings of “Flux! Flux” in the audience. And almost canonical Flux at that. That is our next step.
Flux is an architectural recommendation for structuring React applications. It advocates unidirectional data flow connected to React components (View) and deals with concepts (which we won’t expand on here) like stores that contain data, actions that are triggered by the view and a single dispatcher that translates these actions into store interactions.
So, in this variant of the application, we are going to make a transformation from our naive Flux-less (excellent!) application to still (hopefully less) naive Flux-ful one.
Flux architecture, in the context of our application, may be schematically represented like this:
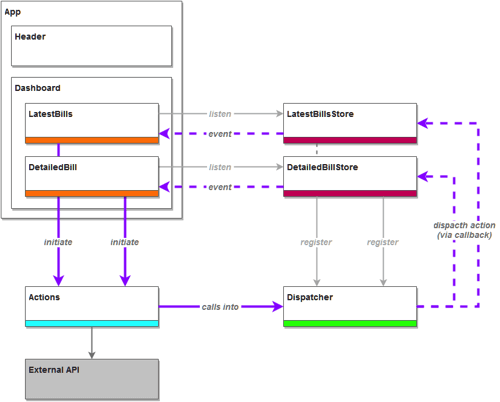
The purple arrows represent the aforementioned unidirectional data flow. To achieve this structure, the following changes were made:
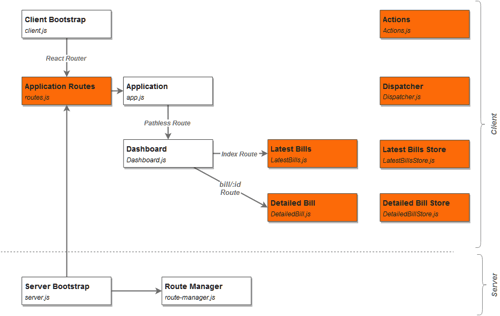
Normally, a Flux implementation would create a connection between a component and its store(s), as well as a connection between a store and the dispatcher.
SomeStore
import AppDispatcher from '../dispatcher/AppDispatcher';
let detailedBillData = {};
export class SomeStore extends EventEmitter {
...
}
...
const SomeStoreInstance = new SomeStore();
...
AppDispatcher.register(function(action) {
switch (action.type) {
case Consts.LOAD_SOME_DATA:
SomeStoreInstance.setAll(action.data);
SomeStoreInstance.emitChange();
break;
...
default:
}
});
SomeComponent
import SomeStoreExample from '../../stores/SomeStore';
import Actions from '../../actions/Actions';
export default class SomeComponent extends React.Component {
...
render() {
...
}
componentWillMount() {
SomeStore.addChangeListener(this.onChange.bind(this));
}
componentWillUnmount() {
SomeStore.removeChangeListener(this.onChange.bind(this));
}
...
onChange() {
const state = SomeStore.getAll();
this.setState(state);
}
}
While this would work perfectly and is generally acceptable, we would like to avoid such a coupling. Let’s try, again, to React-ify this a bit. Let’s create a component! Or a factory of components!
Application code
Server
There are no significant changes in server files.
Client
The “factory” joke from above was not really a joke (and it probably wasn’t funny):
ComponentConnectorFactory.js
export class ComponentConnectorFactory {
connect(options) {
const {component: Component, store: Store, name: name} = options;
const storeInstance = new Store();
AppDispatcher.register(storeInstance.handleAction.bind(storeInstance));
class ComponentConnector extends React.Component {
static get NAME() {
return name;
}
static get contextTypes() {
return {
data: React.PropTypes.object
};
}
static loadAction(params, domain) {
return Component.loadAction(params, domain);
}
constructor(props, context) {
super(props, context);
storeInstance.setAll(context.data[name]);
}
render() {
return <Component {...this.props} store={storeInstance}/>;
}
}
return ComponentConnector;
}
}
export default new ComponentConnectorFactory();
Here, instead of creating up-front a connection between specific stores to the dispatcher to the specific component, we create a dependency injection mechanism of sorts, that will connect these from the outside.
We create, in the connect function, a parent component (a sort of decorator) that envelops the provided component. You can see that all the concerns of context awareness (in contextTypes static method), component name (in NAME), method by which to load the necessary data (loadAction method) store registration and connection between a component and a specific store are abstracted away.
Then we would use it, like you would expect:
routes.js
import LatestBills from './components/bill/LatestBills';
import DetailedBill from './components/bill/DetailedBill';
import DetailedBillStore from './stores/DetailedBillStore';
import LatestBillsStore from './stores/LatestBillsStore';
import ComponentConnectorFactory from './components/common/ComponentConnectorFactory';
const DetailedBillConnector = ComponentConnectorFactory.connect({
name: 'DetailedBillConnector',
component: DetailedBill,
store: DetailedBillStore
});
const LatestsBillsConnector = ComponentConnectorFactory.connect({
name: 'LatestsBillsConnector',
component: LatestBills,
store: LatestBillsStore
});
export default (
<Route path="/" component={App}>
<Route component={Dashboard}>
<IndexRoute component={LatestsBillsConnector}/>
<Route path="bill/:id" component={DetailedBillConnector}/>
</Route>
<Route path="*" component={NoMatch}/>
</Route>
);
Because the …Connector component is a fully fledged React component we can freely use it in our routes definition above, limiting the coupling between stores, components and dispatchers (specific ones) to one place.
There is some symmetry here: we have all navigation concerns centralized in one file, and now we have all wiring/integration concerns concentrated there as well.
LatestBills component would look much simpler and cleaner:
LatestBills.js
...
export default class LatestBills extends React.Component {
static loadAction(params, domain) {
return Actions.loadLatestBillsData(params, domain);
}
constructor(props) {
super(props);
this.changeHandler = this.onChange.bind(this);
this.state = this.props.store.getAll() || {};
}
componentWillMount() {
if (process.browser) {
this.props.store.addChangeListener(this.changeHandler);
}
}
componentWillUnmount() {
this.props.store.removeChangeListener(this.changeHandler);
}
componentDidMount() {
Actions.getLatestBillsData(this.props.params);
}
...
onChange() {
const state = this.props.store.getAll();
this.setState(state);
}
render() {
return (
<section>
<header><h3>Latest Bills</h3></header>
<section>
<List items={this.state.items} itemType={CompactBill}/>
</section>
</section>
);
}
}
Note the process.browser ugliness, due to componentWillMount being executed on both client and server, but componentWillUnmount on client only. This is a great place to introduce memory leaks into your application. Since we don’t actually mount the component and its data retrieval process happens outside of its lifecycle, we can safely skip this method. I couldn’t tell what the reason was to not split this method into two – of which one runs only on server, much like componentDidMount runs only on client, so we are stuck with the ugly.
Note that, if desired, Actions dependency can be extracted as well, but at this point I felt there had to be a clear connection between a component and its actions, so it remained. Also note that loadLatestBillsData method of Actions, the one that is exposed to server in loadAction method – is merely an AJAX call envelope, whereas getLatestBillsData contains application concerns:
Actions.js
export class Actions {
loadDetailedBillData(params, domain = ’) {
const url = `${domain}/api/bill/${params.id}`;
return axios.get(url);
}
getDetailedBillData(params) {
this.loadDetailedBillData(params).then((response) => {
AppDispatcher.dispatch({
type: Consts.LOAD_DETAILED_BILL,
data: response.data
});
}).catch((err) => {
console.log(err);
});
}
...
}
...
LatestBillsStore is also now much simplified:
LatestBillsStore.js
...
let latestBillsData = {};
export default class LatestBillStore extends BaseStore {
resetAll() {
latestBillsData = {};
}
setAll(data) {
latestBillsData = data;
}
getAll() {
return latestBillsData;
}
handleAction(action) {
switch (action.type) {
case Consts.LOAD_LATEST_BILLS:
this.setAll(action.data);
this.emitChange();
break;
default:
}
}
}
where BaseStore extracts common store stuff:
BaseStore.js
export default class BaseStore extends EventEmitter {
static get CHANGE_EVENT() {
return 'CHANGE_EVENT';
}
emitChange() {
this.emit(this.constructor.CHANGE_EVENT);
}
addChangeListener(callback) {
this.on(this.constructor.CHANGE_EVENT, callback);
}
removeChangeListener(callback) {
this.removeListener(this.constructor.CHANGE_EVENT, callback);
}
}
Keep in mind that stores, being singletons, are prone to data leaking, between user sessions, something to keep in mind when considering this or other similar solutions.
4. Conclusion
The evolution steps we’ve gone through above are hardly comprehensive, especially in the area of data retrieval on the server. There is a lot of additional work being done by tools and frameworks that have been inspired and enabled by React: Redux, Relay, Fluxible, Alt and so many, many more.
The examples in this article should get you to the point of being able to be a better judge of how, in your particular application, a server-side rendering solution should be approached.
Dive in and enjoy the ride.